Fall CTF 2023 Guide
Welcome to the Fall CTF 2023 Guide! Feel free to click around the categories as you solve challenges.
Binary Exploitation (pwn)
Introduction
When we run a program, we expect it to take input data, whether it be through files, user input, or internet connections, and produce meaningful output. The code backing the program handles all the logic and control flow within the program. However, either from quirks of the language used, or oversights from the programmer themselves, it's possible to introduce bugs that allow end users of a program to take control of it in unintended ways.
This is the core goal of binary exploitation: Take a binary executable, provide it with input data to take control of its control flow or corrupt its internal structures, and have it do something unintended (and usually unsafe). Executables often interact with files on the host computer, or run other programs (through functions like system or exec). If a user only has an exposed text interface over the network of a running program, it is intended that they are only ever interacting with the program as written. If they provide malicious input that reads secure files, or opens a shell session on the host machine, it suddenly becomes a major security vulnerability for the host machine.
Fall CTF
We have provided a series of challenges designed to explore and teach the fundamentals of how program handle data and control flow, and how unsafe programming practices allow a user to take control of these programs without having access to the host machine, yet able to access the host's filesystem and programs.
Pwn is hard. To begin, you need to be fairly comfortable with programming (or at least understanding code) in a lower level language (like C or C++). This post will attempt to explain underlying structures when running a program, but if you still feel stuck, feel free to ask for help from sigpwny members, or googling around about C functions and syntax. man pages are your friend.
Try each of the challenges, we give the executables and Makefiles for you to run, build, and debug locally. You can build with just make. If you have docker, you can use build a Dockerfile with docker build -t "pwn1" .. Likely for these chals, you won't need a dockerfile. If you get stuck, or unsure how to proceed in any challenge, return here and read each of the following sections carefully. Relevant sections will mention challenges that should be solvable after reading said section, although some additional googling/debugging/trial and error will be necessary.
What is a Stack?
The stack is how programs manage memory per function call. Whenever you define a variable within a function, it's stored on the stack:
int square(int x){
int result = x*x;
return result;
}
int main(){
return square(7);
}
Calling square will store three things on the stack:
- The return pointer
- The base pointer
- The result variable

When square returns, it will pop everything off the stack. This is why you often hear the stack as automatic memory management. We will discuss what base and return pointers are in the next section. For right now, understand that a call to a function stores some bookkeeping for control flow, then all the user defined variables.
gets
gets is a function that requests user input, and saves it to a character buffer. Here's an example:
int main(){
int exit_val = 15
char buf[8];
gets(buf);
return exit_val;
}
gets has a massive security flaw, it does not restrict the number of bytes read. gets doesn't return until you send a terminating character (e.g. newline), thus it'll read over any predefined buffer that you make. Consider the structure of the stack:
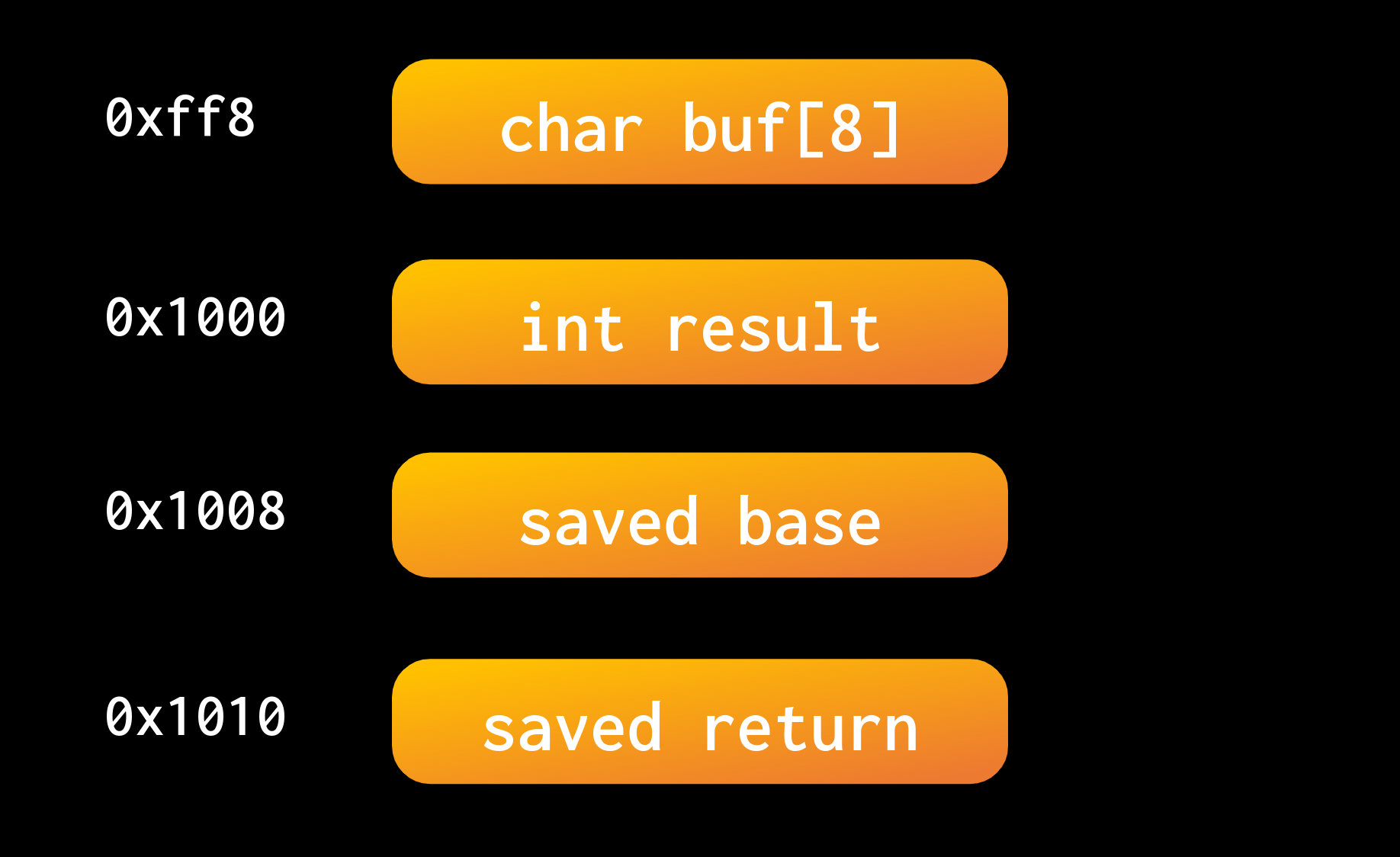
If we read more than 8 bytes (characters), what would happen to result? What about the saved base or return pointers?
We can set the value of these via a Buffer Overflow. If we read more than we have stack storage for, then we'll just continue reading into other saved values. When those saved values get referenced, they'll have values that we control.
Fall CTF
Try to attempt and solve Overflow and Manipulate Challenges. If you get stuck on Return, read on to the next section.
How do Functions Return?
We're going to scope down a bit, and look at a bit of assembly for a function:
leave
ret
This is what the end of a function will look like in assembly. Regardless of whether you are returning a value or not, most functions will terminate with leave then ret. Your processor stores two pointers to the stack in registers. These registers are called rbp and rsp. Normally, they point to the most recent saved Base Pointer, and the top of the Stack.
leave will set rsp to the current value of rbp, which will effectively pop all values off of the stack except for the saved base pointer and saved return pointer. Then, it will pop the saved base pointer into rbp. Now, rsp points to the saved return address.
Our processor has a pointer to program memory of the instruction it is currently executing. This pointer is stored in a register called rip (instruction pointer). Return addresses point to where in the program memory we should jump back to after calling a function. Normally, we calculate this return address right after our function call, then push it to the stack as the signal for a new function stack frame.
When we call ret, we pop the return address off of the stack, and set the instruction pointer (rip) to the return address.
But again, we store the return address on the stack. This means if we have a buffer overflow, can we control where our program returns to?
You can view in gdb or a disassembler the location programs store functions. If you dont want to use such tools, objdump -d challenge will also print out the dissassembly of all the functions, and their hex locations.
Fall CTF
Attempt to do the Return challenge. Once you do, you can read the next section to have the necessary knowledge for Execute and Format
How do Programs Read and Execute Code?
We mentioned before that the processor maintains a position in program memory of the current instruction it is executing. This pointer is again stored in the instruction pointer register: rip. Now, assembly just assembles into bytes. It's just a very simple abstraction layer over actual bytes that the processor reads as machine codes. This means, that the series of bytes c9c3, if read as code, would be the same as leave; ret.
This means that code, is just data. If we choose our data carefully, we can have our processor run meaningful code.
Fall CTF
In the Execute challenge, the stack is executable. What happens when we place code on the stack, and we know the address of the stack?
It might be helpful to google shellcode and shellcode exploits.
Format Vulnerability
printf is a very useful function for printing relevant text, as well as values within our program. If you call printf("hello"), we can expect our program to output "hello". However, we can print values from our program using Format Specifiers. If we include "%d" in our string, we can specify an integer value and print it out as a string:
int x = 15;
printf("%d", x);
Now, our program prints "15". However, in C functions have a fixed number of arguments, right? Well, printf is a variadic function. We can have as many arguments as we need. So if we use %d 3 times, we can place 3 arguments and print all three.
char* buf = "%p%p%p";
printf(buf,ptr1,ptr2,ptr3);
If we directly place a buffer into printf, format specifiers will be handled. The %p specifier will print a number in a pointer format (e.g. 0xcafecafe).
This is extremely unsafe, because if the code doesn't have additional arguments, printf will just look through the stack for all the arguments it needs. If we don't have a stack leak, we could find one by printing values off of the stack until we find a base pointer, and calculate where we need to return to.
One last thing, if we need to use "really far arguments", we can specify positional arguments:
// Prints int4.
printf("%4d",int1,int2,int3,int4,int5)
Fall CTF
Try the Format challenge to leak the stack and run shellcode.
A Primer on pwntools
Introduction
When developing exploits for various challenges, it might be beneficial to use scripts and automation to make your life easier. Especially when you want to deal with sending bytes and data that are not printable, or large numbers when dealing with cryptography.
Of course, one of the easiest scripting languages to use is Python. While you could manually set up connections, text piping, and the whole host of annoying debugging issues that come along with that, there's already a handy library to handle the plumbing for you.
pwntools is a Python library with lots of handy functions, classes, and scripts to help automate and streamline exploit development.
You can install pwntools through pip, Python's package manager:
pip3 install pwntools
or
python3 -m pip install pwntools
Mac/Linux pwntools installation help
If the above command does not work for you on MacOS or Linux, you may need some dependencies that are required to install pwntools. Specifically, pwntools expects you to have cmake and pkg-config. Try running:
brew install cmake
brew install pkg-config
or
sudo apt-get install cmake
sudo apt-get install pkg-config
Interacting with a process
pwntools uses the idea of "tubes" to handle data transfer/receive. You can make a connection with an actual network interface (like you would with netcat), or with a local process, and link standard in and standard out with pwntools.
Here's a few ways to make a connection:
from pwn import * # It's usually just better to import everything when using pwntools
# Start a process on your machine, locally
conn = process('./file')
# Start a process and simultaneously start gdb debugging it.
# You can provide an initial set of commands using the gdbscript parameter
conn2 = gdb.debug('./file', gdbscript="""
b main
continue
""")
# Pause a process running locally and attach gdb to it and start debugging
gdb.attach(conn)
# Connect to a server
port = 22
conn3 = remote('ip.or.domain', port)
With process, it just launches the file specified via the path. If you give it an array of strings, you can run a file with command line arguments, e.g. ['./file', '-t', 'data.txt']. You can also start a program locally with a debugger using gdb.debug() instead. You need to be using a terminal with support for paneling. So install and enter terminal multiplexer such as tmux before running a debugger with pwntools (Windows Terminal, oddly, supports this natively?). You can also attach gdb to an existing process with gdb.attach(). Finally, for communicating with networks (and in our case, challenge servers), you can use remote() to provide an ip/domain and port to connect to.
Once we have our connection, we can send or receive data from it. There are many functions to do this, but I'll show off a few:
from pwn import *
port = 9999
conn = remote('chal.sigpwny.com',port)
# Receive functions will return a bytestring of what it receives.
# Receive text until it encounters a new line character (e.g. \n)
line = conn.recvline()
# Receive text until it encounters the specified delimiter.
prompt = conn.recvuntil(b'>> ')
# Receive exactly n bytes.
resp = conn.recvn(8)
# Receive everything until End of File (EOF) is received from the pipe (i.e. they closed the connection)
everything = conn.recvall()
# Sends the string along with an new line ending
conn.sendline(b'my response\x05\x0f\xa0')
# Does NOT send a newline
conn.send(b'not a line yet')
# Does a recvuntil('delim') and sends the 2nd argument
conn.sendlineafter(b'>> ', b'1')
Note that strings in these functions are bytestrings b''. pwntools will warn you if you dont use bytestrings, and automatically convert to ASCII.
That being said, this means its really easy to send non-printable characters over the wire using \x escape. It's also important to keep in mind that functions looking for a specific character (like a new line or delimiter), will block until it does. If your script is stuck, check to see whether or not you are actually getting the text you think you are. Running the script with the DEBUG argument will cause it to print a hex dump of any data it sends/receives: python3 exploit.py DEBUG
Note, pipes with processes and such are buffered. The OS maintains a 4kb buffer of any text received. If you call recvline(), and the program sent 3 lines in total, only the first line is retrieved, and the other 2 remain in the buffer. Keep this in mind when processing received data. If you want to retrieve anything that's in the buffer currently, recv() will empty it out.
Finally, if you want to regain control of the process input/output, simply call:
conn.interactive()
You'll want this to read the final printout of a program after running your exploit, or to use a shell, etc.
Using shellcode
For some of our challenges, you will need to use pwntools asm function. This requires a binutils installation for the architecture that our machines are running on, in this case, amd64. If you are on an M1/M2 mac, you'll need to run the following commands somewhere to generate assembly for our servers:
wget https://raw.githubusercontent.com/Gallopsled/pwntools-binutils/master/macos/binutils-amd64.rb
brew install binutils-amd64.rb
Web
We have run two web meeting this semester:
Website Structure
Websites use three main languages: HTML, CSS, and Javascript. HTML is the skeleton of the website, and organizes each of the different elements onto the user's screen. CSS is how you edit and develop the styles on a website. The most important and widely used language within the web is Javascript. Javascript allows you to dynamically change elements within your site, have something happen when a button is pressed, or make a requests to other computers.
Client-Server Model
When you click on a link within your browser, your computer makes a request to a server located at the address of the link you clicked. This request is then processed on the server's side, and the server sends back the webpage you want to load. This is the Client-Server Model. By manipulating processes within this model's process, you can access extra content on either the server or client side!
When content is sent between your computer and the server, it includes additional metadata called "Headers". Some of this data remains in your browser, either as cookies or local storage (technically more kinds).
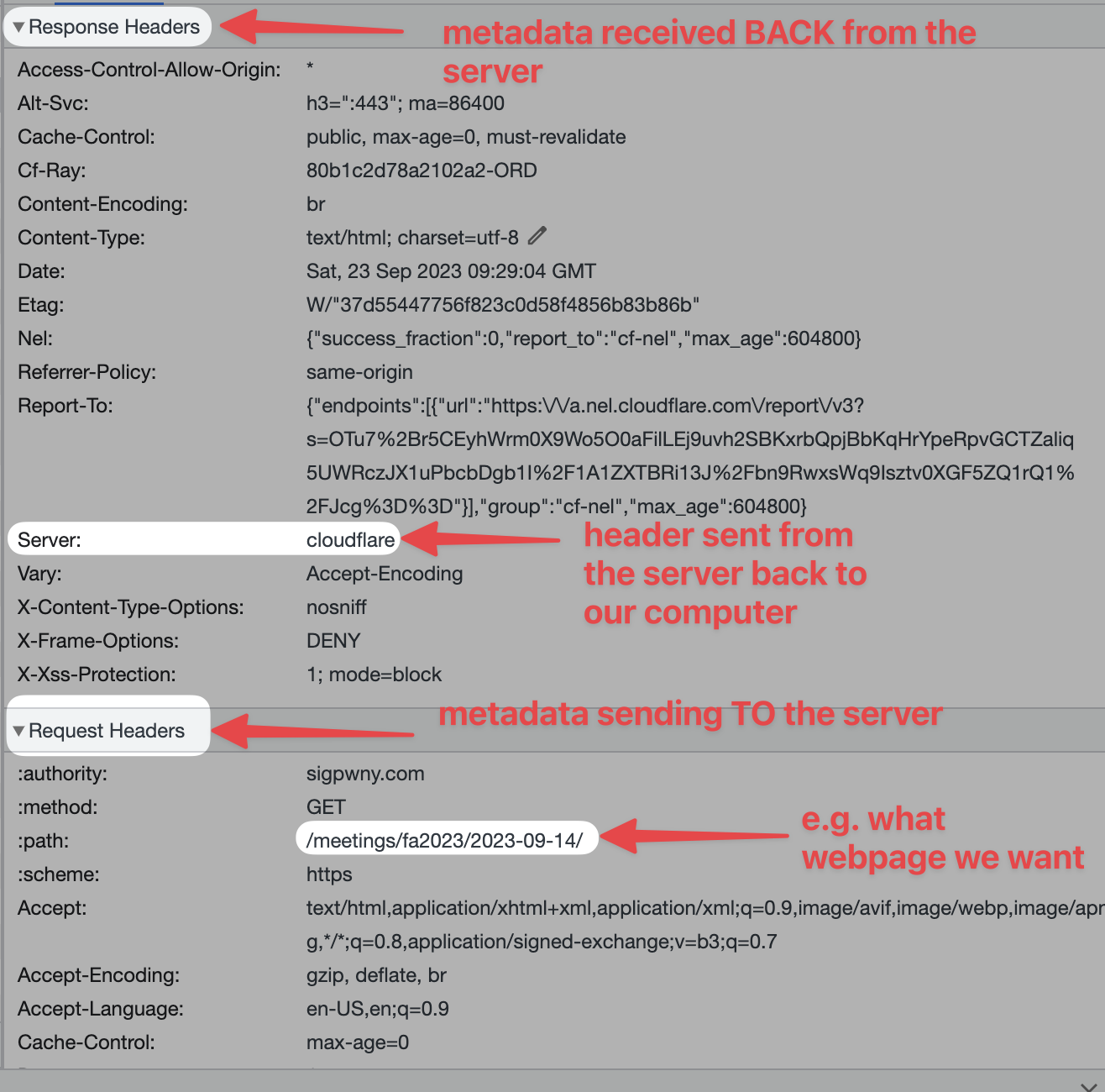
- Cookies are saved per website, and are sent in each request. They can be changed by Javascript or a request header.
- Local Storage is saved per website, but are not sent in each request. They can be changed by Javascript in your browser.
Devtools
Developer tools is how you view additional website about an information. For our challenges, we reccommend you download Chrome or Firefox, and not use Safari.
To open devtools, hit Ctrl + Shift + C (windows) or Command + Shift + C (mac). Alternatively, right click and hit inspect.
Chrome Devtools is a suite of software developer information for web development. During challenges, you will be able to poke around different tabs. Here are some helpful tabs to lookout for:
- Console (you can run your own javascript in this tab)
Pro Tip: You can use breakpoints within the console by clicking next to the line number. This can allow you to stop at certain lines before the run and check variables
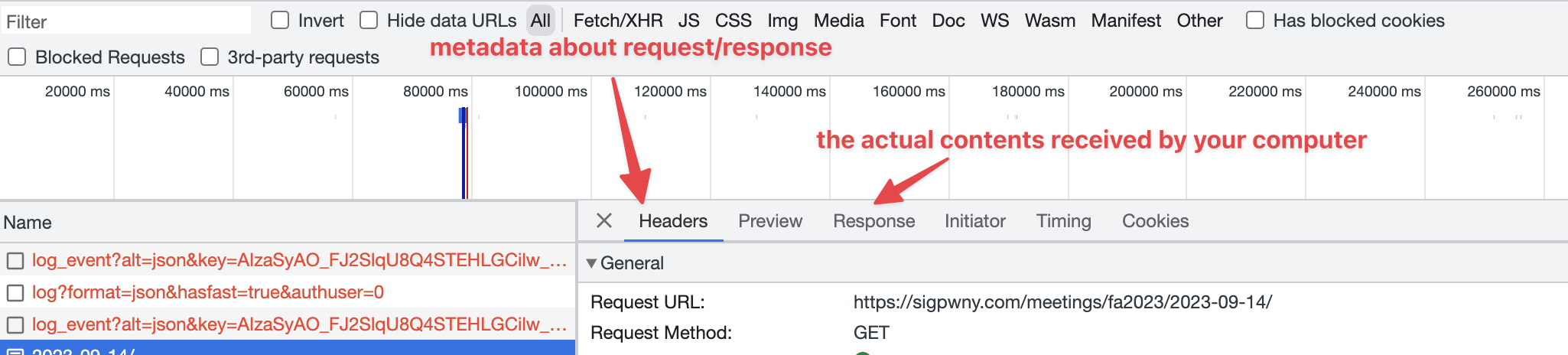
- Network
The network tab shows all information transmitted to/from your computer to the server (website).

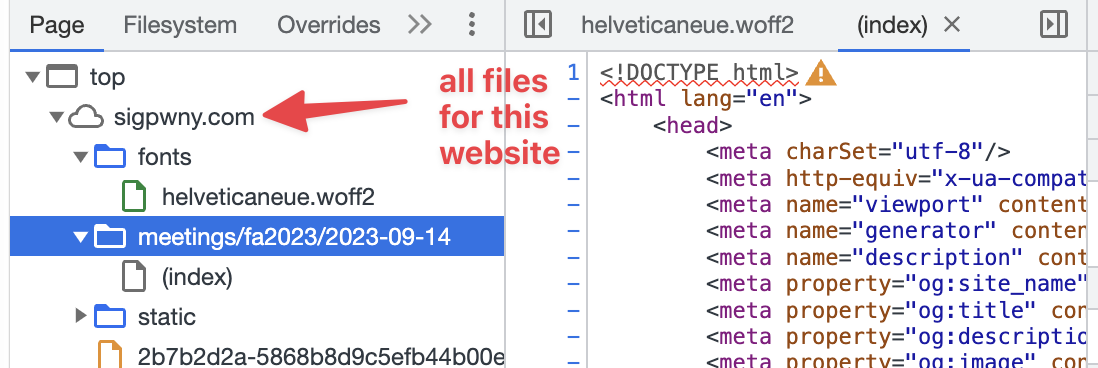
- Sources
The sources tab shows a listing of all files on the server that were requested.
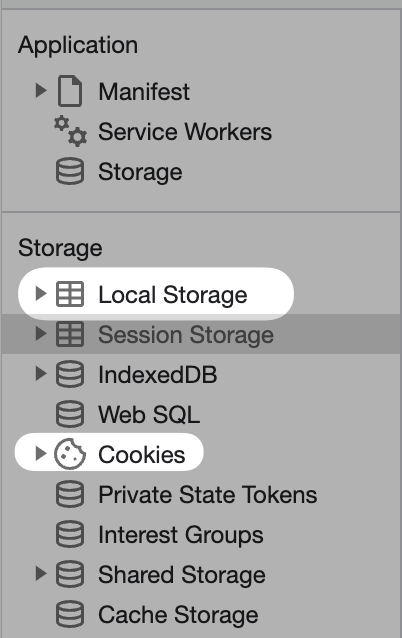
- Application
The application tab shows the saved cookies, local storage, and other information stored in your browser.
This is not an exhaustive list, but just a few useful tabs within Devtools.
Encodings you should know about:
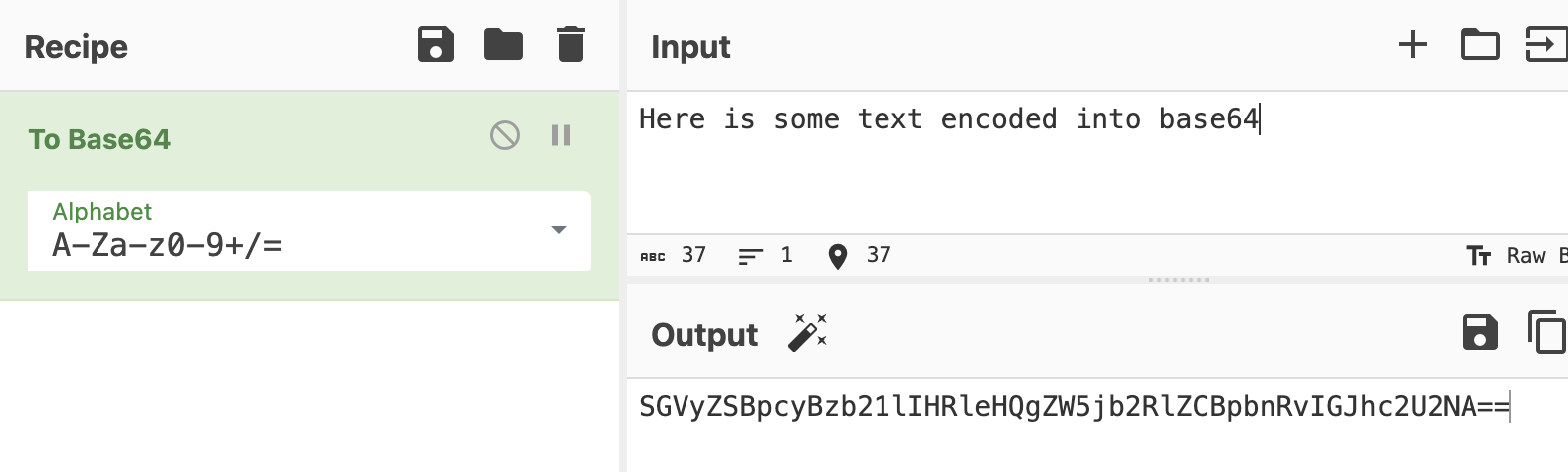
base64 - Looks like this
url encoding - Looks like this
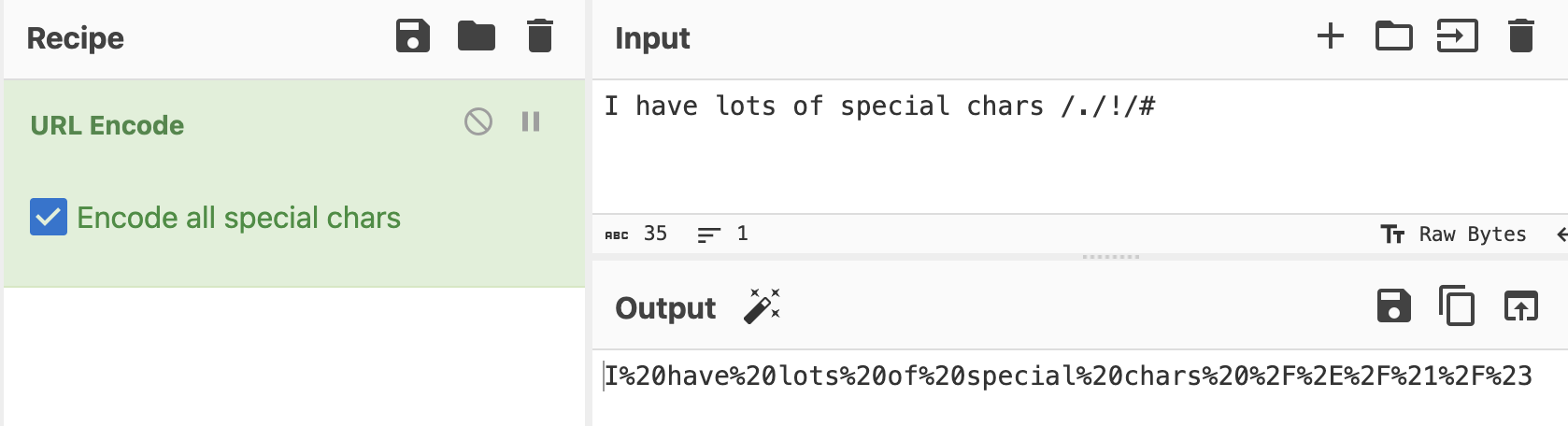
You can use CyberChef to decode.
SQL Injections
More in-depth explanations can be found in the Web 2 slides about SQL.
SQL, or Structured Query Language is a language for fetching information from a server.
For example,
SELECT netid, firstname FROM students WHERE lastname = "Tables"

If code is written incorrectly, you can modify an SQL Statement as shown above.
More details on SQL: https://portswigger.net/web-security/sql-injection Resource on SQL Union Attack: https://portswigger.net/web-security/sql-injection/union-attacks
Command Injections
Command Injection lets you execute multiple linux commands at the same time. It is very similar to SQL Injection, except instead of changing a database query, you are changing commands executed in the command line.
For example, in your terminal, you are able to execute multiple commands using the ; ability
$> echo "command 1"; echo "command 2"
command 1
command 2
If you are able to "inject" something directly into the command you are executing, you can make it do additional things.
$> echo "YOUR INPUT"
If I had set YOUR INPUT to -HI"; ls ; "BYE-
then the command would look like
echo "-HI"; ls; "BYE-"
Some useful commands are:
ls- list filescat x.txt- output the contents of the filex.txt
If you want more resources on learning the linux command line...
- Review our Setup/Terminal Meeting Slides